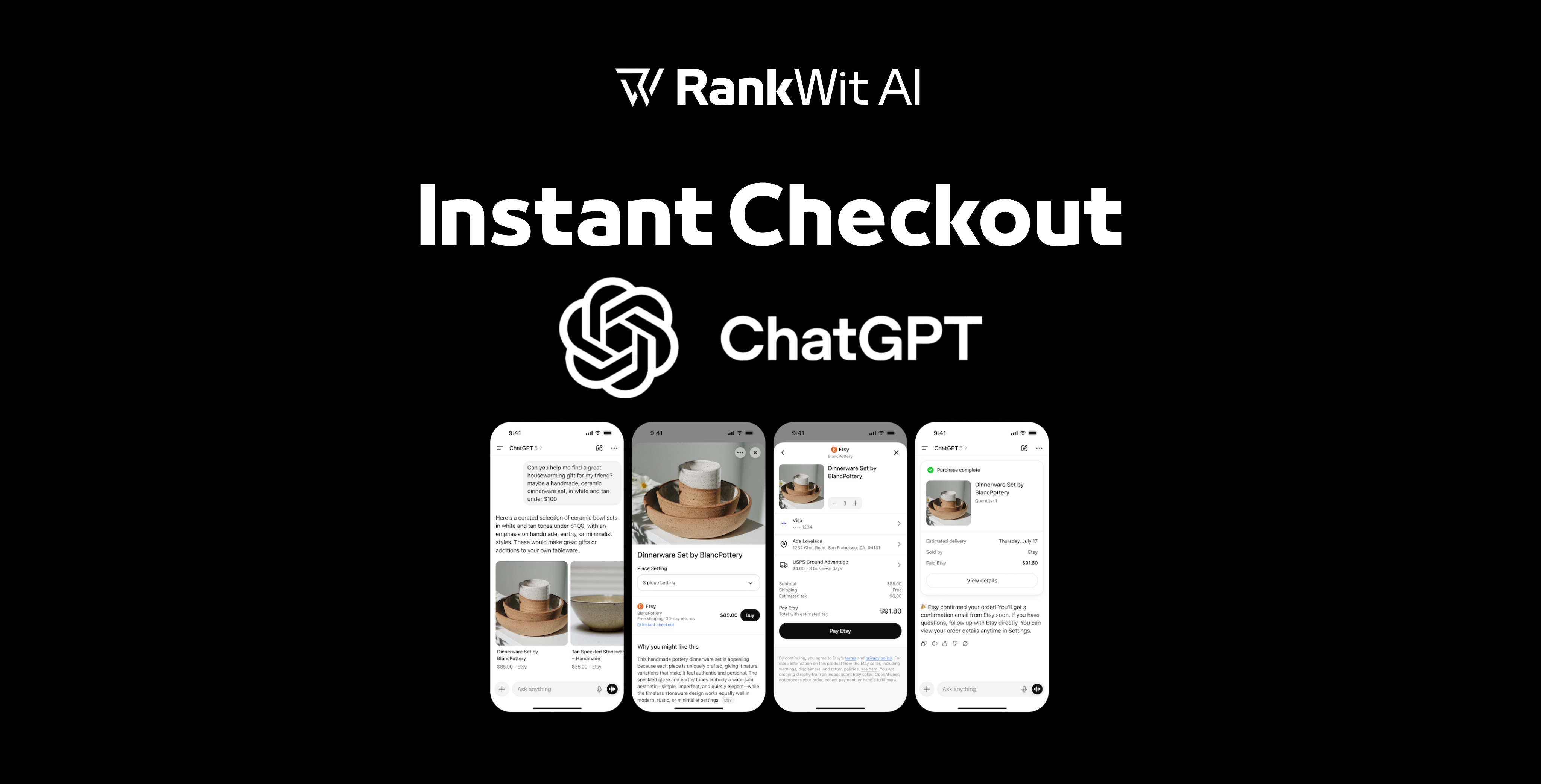
Retrieval-Augmented Generation (RAG) nel 2025: architetture, framework e applicazioni industriali
Last updated:
August 18, 2025
Autore:

.svg)
La Retrieval-Augmented Generation (RAG) è emersa come una delle strategie più potenti per migliorare i Large Language Models (LLM).
Combinando recupero delle conoscenze con ragionamento generativo, i sistemi RAG riducono le allucinazioni, migliorano la precisione e forniscono un'intelligenza specifica del dominio che i modelli statici non possono eguagliare.
Dalla sua introduzione nel 2020, RAG si è evoluta rapidamente.
Nel 2025, stiamo assistendo a un'ondata di innovazione:
Parallelamente a questi progressi della ricerca, sono maturate le pratiche di implementazione aziendale e i benchmark di valutazione, rendendo RAG centrale nei sistemi di intelligenza artificiale di livello di produzione.
RAG si sta evolvendo da una tecnica promettente a una necessità aziendale e allo stesso tempo sta incontrando nuove limitazioni. Includi una prospettiva recente:
«RAG non è più solo un miglioramento per i chatbot di intelligenza artificiale: è la spina dorsale strategica della gestione della conoscenza aziendale e dell'accesso alla conoscenza. Man mano che l'intelligenza artificiale passa dalla novità alla necessità, RAG offre un modo ripetibile e scalabile per portare l'intelligenza al centro del lavoro, ad esempio semplificando l'analisi degli investimenti». Scoiattolo
Menziona anche il ruolo fondamentale della gestione dei documenti (DM) nel consentire un'efficace implementazione dei RAG:
«I RAG offrono il massimo valore se abbinati a un solido sistema di gestione dei documenti. In effetti, RAG dà il massimo della sua potenza se combinato con la ricerca di metadati, offrendo agli utenti un modo preciso per approfondire lo spazio informativo della propria organizzazione»TechRadar
Questo articolo esplora i ricerche, framework, benchmark e casi d'uso di settore all'avanguardia che definiscono il panorama RAG oggi.
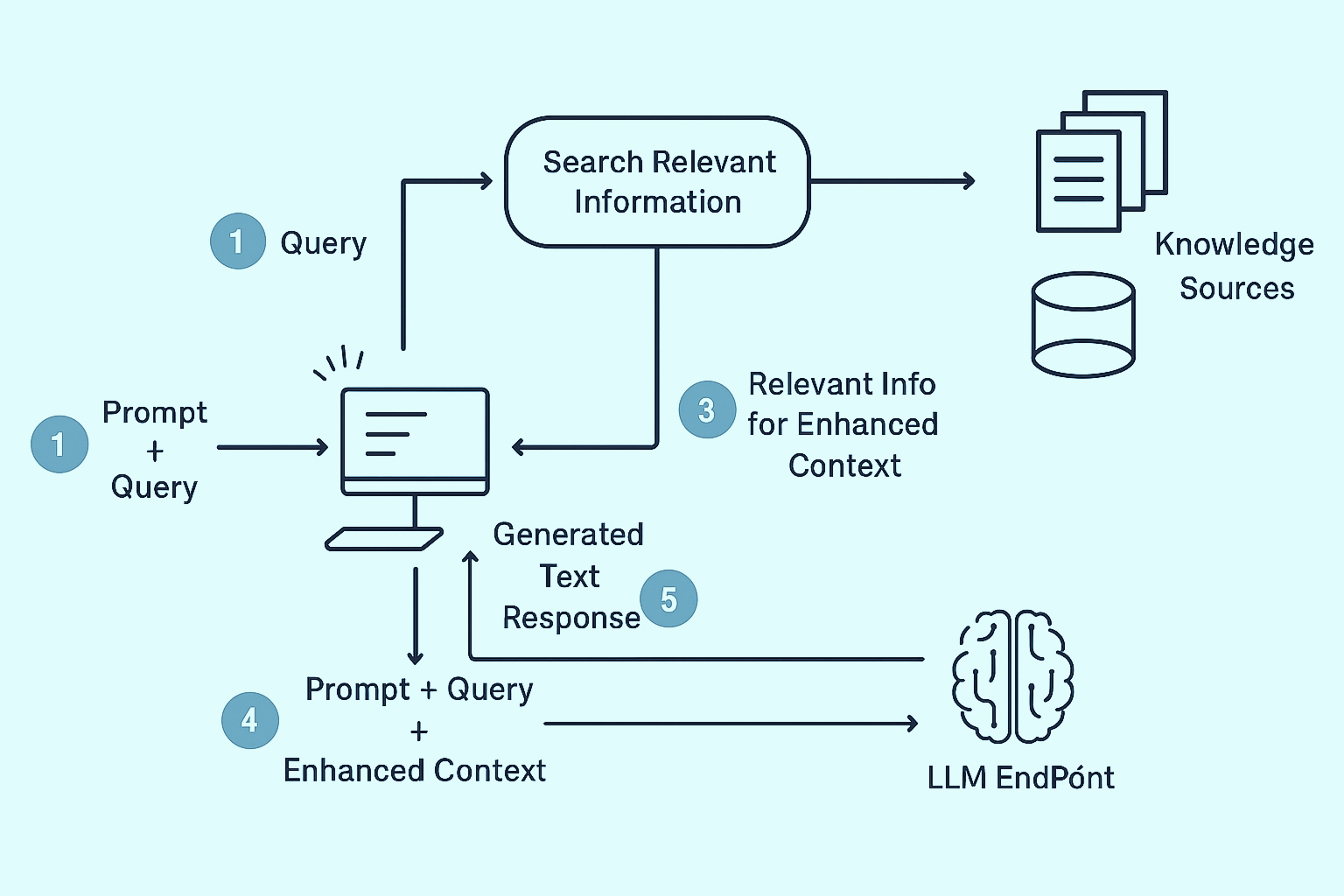
Fondamentalmente, RAG migliora i modelli generativi con conoscenze esterne.
Invece di fare affidamento esclusivamente su parametri predefiniti, un sistema RAG recupera documenti, passaggi o dati pertinenti da fonti esterne e li inserisce nella finestra di contesto del LLM prima di generare una risposta.
Questo approccio risolve tre limiti principali degli LLM autonomi:
Come il Documento antologico ACL Alla ricerca delle migliori pratiche nella generazione aumentata di recupero punti salienti,
«RAG non è un metodo singolo ma uno spazio di progettazione di architetture e strategie di recupero» che può essere ottimizzato per diverse attività.
Sviluppato da Microsoft Research, GraphRag integra i grafici della conoscenza direttamente nelle pipeline di recupero, consentendo agli LLM di connetti le relazioni, non solo recupera fatti.
Questo ragionamento strutturato lo rende particolarmente efficace per i domini che richiedono inferenze complesse, come scoperta scientifica, conformità normativa e rilevamento delle frodi.
Mini Strag adatta l'aumento del recupero per Modelli in piccolo linguaggio (SLM), fornendo pipeline efficienti che prosperano in ambienti con poche risorse.
Portando RAG a dispositivi edge, sistemi IoT e applicazioni integrate, sblocca le funzionalità di intelligenza artificiale oltre il cloud, dove l'intelligenza leggera è più importante.
VideoRag spinge RAG nell'era multimodale, combinando incorporamenti visivi e metadati testuali per recuperare segmenti video pertinenti su richiesta.
Questo lo rende un punto di svolta per piattaforme di apprendimento basate su video, analisi di sorveglianza e motori di ricerca multimediali personalizzati.
Man mano che le aziende utilizzano RAG in contesti sensibili, Sacca sicura emerge come un stress test di sicurezza per le condotte di recupero.
Confronta la resilienza con perdita di dati, pronta iniezione e manipolazione contraddittoria, aiutando le organizzazioni a creare sistemi di intelligenza artificiale non solo intelligenti, ma anche affidabile e sicuro.
RAG Agentic introduce agenti che sfruttano il recupero come parte di flussi di lavoro in più fasi.
Questo paradigma consente processo decisionale dinamico, utile nell'automazione aziendale, nel ragionamento legale e nella risposta a domande multi-hop.
Diversi framework open source domineranno lo sviluppo di RAG nel 2025:
Per i principianti, Hugging Face's «RAG da zero» il tutorial offre un ottimo punto di partenza, mentre la guida avanzata di Zen van Riel fornisce approfondimenti sull'architettura e sull'implementazione della produzione.
Le implementazioni aziendali di RAG richiedono molto più del semplice collegamento a un database vettoriale. Le migliori pratiche includono:
Come osserva AWS Prescriptive Guidance:
«il database e la strategia di implementazione giusti possono fare la differenza tra un proof-of-concept e un sistema RAG pronto per la produzione».
Il benchmarking è ormai una disciplina consolidata nella ricerca RAG:
Questi framework consentono ai ricercatori e alle aziende di convalidare i sistemi RAG non solo in termini di precisione, ma anche di robustezza, latenza e sicurezza.
RAG sta trasformando diversi settori:
Queste storie di successo dimostrano il valore di RAG non solo nella ricerca ma anche nell'impatto aziendale.
RAG si è evoluto da prototipo di ricerca a pietra miliare dell'IA aziendale.
Le scoperte del 2025, da GraphRag a RAG Agentic, dimostrano che l'aumento del recupero è non è più opzionale, ma essenziale per preciso, sicuroe sistemi di intelligenza artificiale scalabili.
Per le aziende, l'opportunità non sta solo nell'adottare RAG ma in scelta dei framework, dei database vettoriali e delle strategie di distribuzione giusti.
Con la maturazione dell'ecosistema, le organizzazioni che integrano RAG in modo efficace stabiliranno lo standard per applicazioni AI intelligenti e affidabili.
RAG (Generazione aumentata di recupero) è una tecnica di intelligenza artificiale all'avanguardia che migliora i modelli linguistici tradizionali integrando un sistema esterno di ricerca o recupero delle conoscenze. Invece di affidarsi esclusivamente a dati preaddestrati, un modello abilitato al RAG può ricerca in un database o in una fonte di conoscenza in tempo reale e utilizza i risultati per generare risposte più accurate e contestualmente pertinenti.
Per GEO, questo è un punto di svolta.
GEO non risponde solo con un linguaggio generico, ma recupera informazioni fresche e pertinenti dalla knowledge base, dai documenti o dai contenuti web esterni della tua azienda prima di generare la risposta. Ciò significa:
Combinando i punti di forza della generazione e recupero, RAG assicura che GEO non si limita suono intelligente—esso è intelligente, in linea con la tua fonte di verità.
Ottimizzazione generativa del motore (GEO) — noto anche come Ottimizzazione dei modelli linguistici di grandi dimensioni (LLMO) — è il processo di ottimizzazione dei contenuti per aumentarne la visibilità e la pertinenza all'interno delle risposte generate dall'intelligenza artificiale da strumenti come ChatGPT, Gemini o Perplexity.
A differenza della SEO tradizionale, che mira al posizionamento nei motori di ricerca, GEO si concentra su come i modelli linguistici di grandi dimensioni interpretano, assegnano priorità e presentano le informazioni agli utenti in output conversazionali. L'obiettivo è influenzare come e quando i contenuti vengono visualizzati nelle risposte basate sull'intelligenza artificiale.
Le trasformatore è l'architettura fondamentale alla base dei moderni LLM come GPT. Introdotti in un innovativo documento di ricerca del 2017, i trasformatori hanno rivoluzionato l'elaborazione del linguaggio naturale consentendo ai modelli di considerare l'intero contesto di una frase contemporaneamente, piuttosto che semplici sequenze parola per parola.
L'innovazione chiave è meccanismo di attenzione, che aiuta il modello a decidere quali parole di una frase sono più pertinenti l'una per l'altra, imitando essenzialmente il modo in cui gli umani prestano attenzione a dettagli specifici in una conversazione.
I trasformatori consentono agli LLM di generare risposte più coerenti, consapevoli del contesto e accurate.
Ecco perché oggi sono al centro della maggior parte dei modelli linguistici all'avanguardia.
Il GEO richiede un cambio di strategia rispetto alla SEO tradizionale. Invece di concentrarti esclusivamente su come i motori di ricerca scansionano e classificano le pagine, Ottimizzazione generativa del motore (GEO) si concentra su come Modelli linguistici di grandi dimensioni (LLM) come ChatGPT, Gemini o Claude comprendere, recuperare e riprodurre informazioni nelle loro risposte.
Per semplificare l'implementazione, possiamo applicare i tre pilastri classici della SEO:Semantica, Tecnicoe Autorità/collegamenti—reinterpretata attraverso la lente di GEO.
Questo si riferisce al linguaggio, struttura e chiarezza del contenuto stesso: cosa scrivi e come lo scrivi.
🧠 Tattiche GEO:
🔍 Rispetto alla SEO tradizionale:
Questo pilastro riguarda il modo in cui sono i tuoi contenuti codificato, consegnato e accessibile—non solo dagli umani, ma anche dai modelli di intelligenza artificiale.
⚙️ Tattiche GEO:
🔍 Rispetto alla SEO tradizionale:
Questo si riferisce al segnali di fiducia che indicano a un modello, o a un motore di ricerca, che i tuoi contenuti sono affidabili.
🔗 Tattiche GEO:
🔍 Rispetto alla SEO tradizionale:
Agentic RAG rappresenta un nuovo paradigma in Generazione aumentata di recupero (RAG).
Mentre il RAG tradizionale recupera le informazioni per migliorare l'accuratezza degli output del modello, Agentic RAG fa un ulteriore passo avanti integrando agenti autonomi in grado di pianificare, ragionare e agire in flussi di lavoro in più fasi.
Questo approccio consente ai sistemi di:
In altre parole, Agentic RAG non solo fornisce risposte migliori, ma gestisce strategicamente il processo di recupero per supportare processo decisionale più accurato, efficiente e spiegabile.