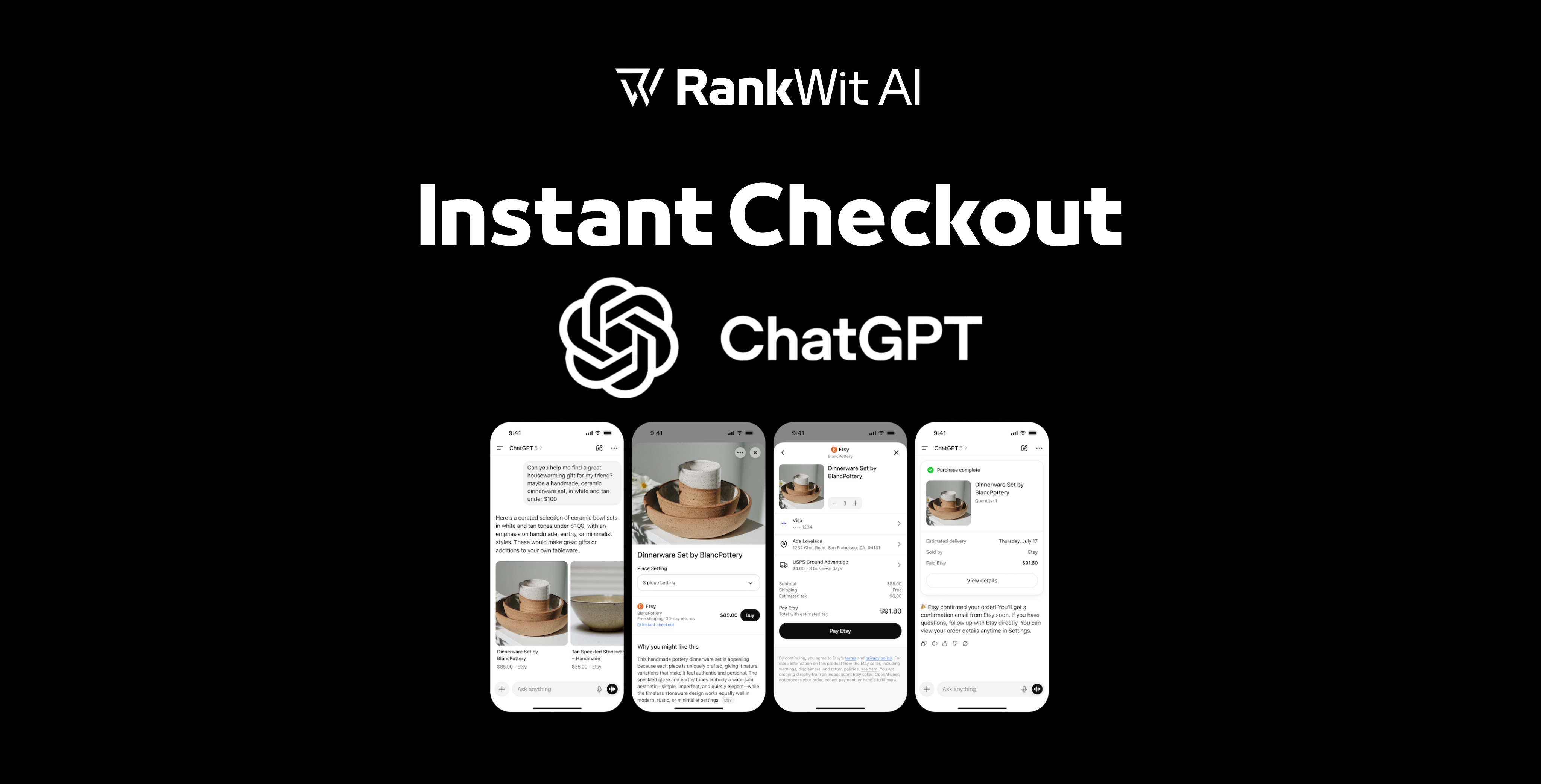
Retrieval-Augmented Generation
Last updated:
August 18, 2025
Author:

.svg)
Retrieval-Augmented Generation (RAG) has emerged as one of the most powerful strategies for enhancing Large Language Models (LLMs).
By combining knowledge retrieval with generative reasoning, RAG systems reduce hallucinations, improve accuracy, and provide domain-specific intelligence that static models cannot match.
Since its introduction in 2020, RAG has evolved rapidly.
In 2025, we are witnessing a surge of innovation:
Alongside these research advances, enterprise deployment practices and evaluation benchmarks have matured, making RAG central to production-grade AI systems.
RAG is evolving from a promising technique to an enterprise necessity—and simultaneously encountering new limitations. Include a recent perspective:
"RAG is no longer just an enhancement for AI chatbots – it’s the strategic backbone of enterprise knowledge management and knowledge access. As AI moves from novelty to necessity, RAG offers a repeatable, scalable way to bring intelligence to the point of work, for example by streamlining investment analysis." Squirro
Also mention the critical role of document management (DM) in enabling effective RAG deployment:
"RAG deliver the most value when paired with a robust document management system. In fact, RAG is at its most powerful when layered with metadata search, giving users a precise way to drill into their organization’s information space"TechRadar
This article explores the cutting-edge research, frameworks, benchmarks, and industry use cases that define the RAG landscape today.
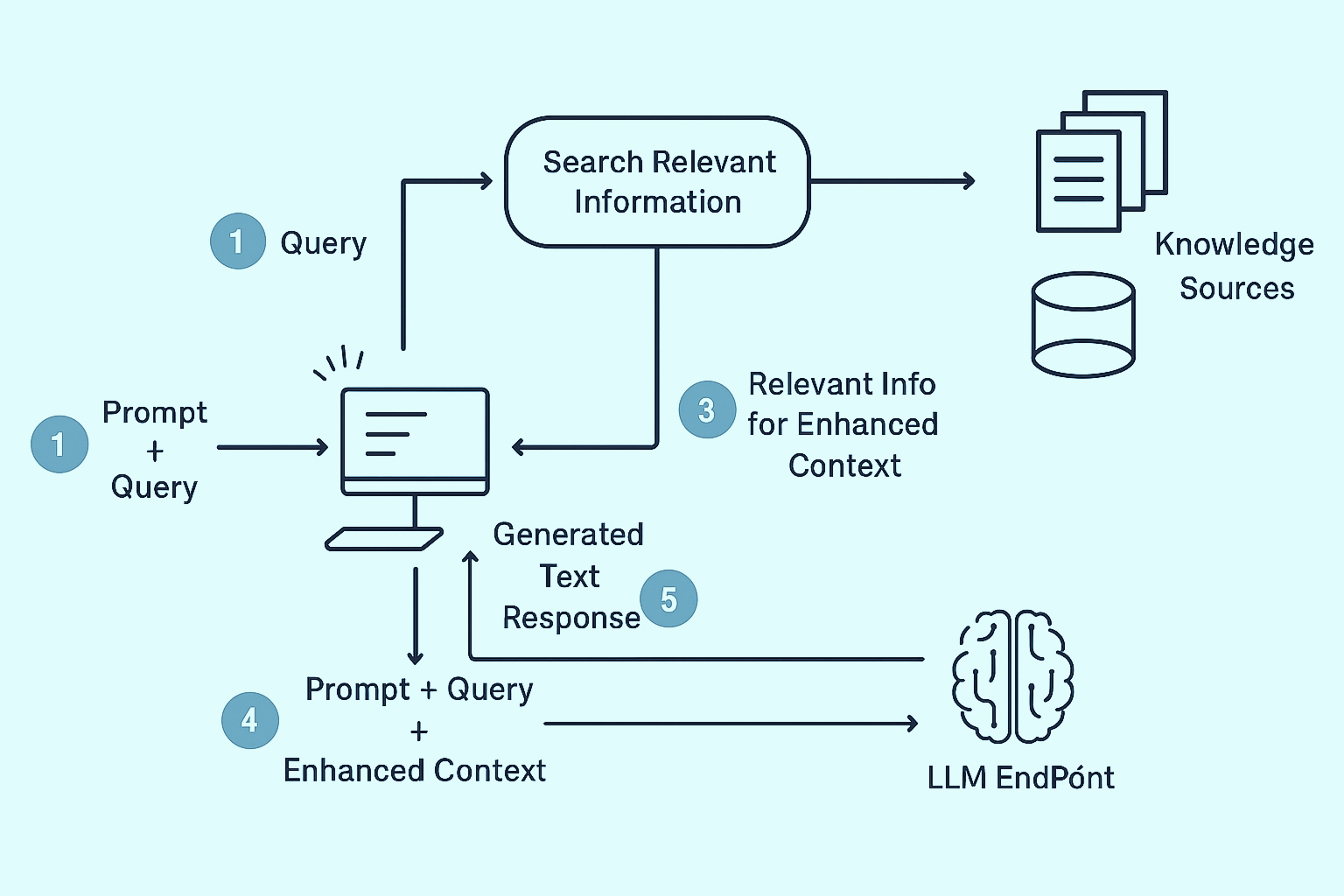
At its core, RAG enhances generative models with external knowledge.
Instead of relying solely on pretrained parameters, a RAG system retrieves relevant documents, passages, or data from external sources, and injects them into the LLM’s context window before generating an answer.
This approach addresses three major limitations of standalone LLMs:
As the ACL Anthology paper Searching for Best Practices in Retrieval-Augmented Generation highlights,
“RAG is not a single method but a design space of architectures and retrieval strategies” that can be optimized for diverse tasks.
Developed by Microsoft Research, GraphRAG weaves knowledge graphs directly into retrieval pipelines, enabling LLMs to connect relationships, not just retrieve facts.
This structured reasoning makes it especially powerful for domains that demand complex inference, such as scientific discovery, regulatory compliance, and fraud detection.
MiniRAG adapts retrieval augmentation for Small Language Models (SLMs), delivering efficient pipelines that thrive in low-resource environments.
By bringing RAG to edge devices, IoT systems, and embedded applications, it unlocks AI capabilities beyond the cloud, where lightweight intelligence matters most.
VideoRAG pushes RAG into the multimodal era, combining visual embeddings and textual metadata to retrieve relevant video segments on demand.
This makes it a game-changer for video-based learning platforms, surveillance analytics, and personalized media search engines.
As enterprises deploy RAG in sensitive settings, SafeRAG emerges as a security stress test for retrieval pipelines.
It benchmarks resilience against data leakage, prompt injection, and adversarial manipulation, helping organizations build AI systems that are not only intelligent, but also trustworthy and secure.
Agentic RAG introduces agents that leverage retrieval as part of multi-step workflows.
This paradigm enables dynamic decision-making, valuable in enterprise automation, legal reasoning, and multi-hop question answering.
Several open-source frameworks dominate RAG development in 2025:
For beginners, Hugging Face’s “RAG from scratch” tutorial offers an excellent starting point, while Zen van Riel’s advanced guide provides deep insights into architecture and production deployment.
Enterprise deployments of RAG require more than just plugging in a vector database. Best practices include:
As AWS Prescriptive Guidance notes:
“the right database and deployment strategy can make the difference between a proof-of-concept and a production-ready RAG system.”
Benchmarking is now an established discipline in RAG research:
These frameworks allow researchers and enterprises to validate RAG systems not only on accuracy, but also on robustness, latency, and security.
RAG is transforming multiple industries:
These success stories demonstrate RAG’s value not only in research but also in enterprise impact.
RAG has evolved from a research prototype into a cornerstone of enterprise AI.
The breakthroughs of 2025, from GraphRAG to Agentic RAG, demonstrate that retrieval augmentation is no longer optional, but essential for accurate, secure, and scalable AI systems.
For businesses, the opportunity lies not only in adopting RAG but in choosing the right frameworks, vector databases, and deployment strategies.
As the ecosystem matures, organizations that integrate RAG effectively will set the standard for intelligent, trustworthy AI applications.
RAG (Retrieval-Augmented Generation) is a cutting-edge AI technique that enhances traditional language models by integrating an external search or knowledge retrieval system. Instead of relying solely on pre-trained data, a RAG-enabled model can search a database or knowledge source in real time and use the results to generate more accurate, contextually relevant answers.
For GEO, this is a game changer.
GEO doesn't just respond with generic language—it retrieves fresh, relevant insights from your company’s knowledge base, documents, or external web content before generating its reply. This means:
By combining the strengths of generation and retrieval, RAG ensures GEO doesn't just sound smart—it is smart, aligned with your source of truth.
Generative Engine Optimization (GEO), also known as Large Language Model Optimization (LLMO), is the process of optimizing content to increase its visibility and relevance within AI-generated responses from tools like ChatGPT, Gemini, or Perplexity.
Unlike traditional SEO, which targets search engine rankings, GEO focuses on how large language models interpret, prioritize, and present information to users in conversational outputs. The goal is to influence how and when content appears in AI-driven answers.
The transformer is the foundational architecture behind modern LLMs like GPT. Introduced in a groundbreaking 2017 research paper, transformers revolutionized natural language processing by allowing models to consider the entire context of a sentence at once, rather than just word-by-word sequences.
The key innovation is the attention mechanism, which helps the model decide which words in a sentence are most relevant to each other, essentially mimicking how humans pay attention to specific details in a conversation.
Transformers make it possible for LLMs to generate more coherent, context-aware, and accurate responses.
This is why they're at the heart of most state-of-the-art language models today.
GEO requires a shift in strategy from traditional SEO. Instead of focusing solely on how search engines crawl and rank pages, Generative Engine Optimization (GEO) focuses on how Large Language Models (LLMs) like ChatGPT, Gemini, or Claude understand, retrieve, and reproduce information in their answers.
To make this easier to implement, we can apply the three classic pillars of SEO—Semantic, Technical, and Authority/Links—reinterpreted through the lens of GEO.
This refers to the language, structure, and clarity of the content itself—what you write and how you write it.
🧠 GEO Tactics:
🔍 Compared to Traditional SEO:
This pillar deals with how your content is coded, delivered, and accessed—not just by humans, but by AI models too.
⚙️ GEO Tactics:
🔍 Compared to Traditional SEO:
This refers to the signals of trust that tell a model—or a search engine—that your content is reliable.
🔗 GEO Tactics:
🔍 Compared to Traditional SEO:
Agentic RAG represents a new paradigm in Retrieval-Augmented Generation (RAG).
While traditional RAG retrieves information to improve the accuracy of model outputs, Agentic RAG goes a step further by integrating autonomous agents that can plan, reason, and act across multi-step workflows.
This approach allows systems to:
In other words, Agentic RAG doesn’t just provide better answers, but it strategically manages the retrieval process to support more accurate, efficient, and explainable decision-making.