Come funzionano i motori di ricerca: dalla scansione al posizionamento
Last updated:
August 21, 2025
Autore:

.svg)
Quando digiti una domanda in una barra di ricerca, ciò che accade dopo sembra magico. Esistono miliardi di pagine sul Web, eppure in qualche modo le migliori appaiono immediatamente davanti a te. Per capirlo, entriamo nel mondo della scansione, dell'indicizzazione e del posizionamento, non come semplici passaggi, ma come una storia di come le macchine riescano a mettere ordine nel caos di Internet.
Pensa a Internet come a un grafico infinito:
G= (V, E) G= (V, E)dove V rappresenta le pagine Web (nodi) e E rappresenta i collegamenti (bordi).
I motori di ricerca utilizzano «crawler», che si spostano da un nodo all'altro seguendo i bordi. Proprio come un random walker nella teoria dei grafi, un crawler ha una distribuzione di probabilità di visitare una nuova pagina:
P (vu) =1/uscita (u)
significa la possibilità di visitare la pagina v dalla pagina uu dipende da quanti link in uscita u ha.
In pratica, i crawler non si muovono in modo casuale: danno priorità alla freschezza, all'autorità e all'importanza delle pagine. Ma in fondo, la scansione è il processo di scoperta dei nodi in questo enorme grafico web.
Una volta scoperta, ogni pagina deve essere archiviata e organizzata. L'indicizzazione trasforma l'HTML grezzo in informazioni strutturate. Immagina l'indice come una funzione:
i:WORD→ {pagine contenenti parole}Ad esempio:
I («AI») = {p1, p2, p3,...}Questo si chiama indice invertito—invece di mappare le pagine in parole, associa le parole alle pagine.
Proprio come un catalogo di una biblioteca, consente il recupero immediato. Quando si cerca «come funzionano i motori», il sistema interseca questi insiemi:
I («come») I («motori») I («lavoro»)e recupera solo i documenti che li contengono tutti e tre.
Ora arriva l'arte e la matematica della classifica. Non tutte le pagine sono uguali. Alcune sono più autorevoli, altre sono più pertinenti. La classifica unisce più segnali in una funzione di punteggio:
S (d, q) =P 1 r (d, q) +P 2 A (d) +P 3 u (d)dove:
R (d, q) = Rilevanza del documento dd per l'interrogazione qqA (d) = Autorità del documento (basata su backlink, fiducia, ecc.)U (d) = Segnali relativi all'esperienza utente (velocità, compatibilità con i dispositivi mobili, coinvolgimento)w1, w2, w3 = pesi regolati dal motore di ricercaUna famosa formula iniziale è PageRank. In forma semplificata, l'importanza di una pagina PP è data da:
PR (P) =1−D/N+D*L (Q) PR (Q) (QSURM (P))
dove:
d = fattore di smorzamento (di solito ~0,85)N = numero totale di pagineM (P) = set di pagine che rimandano a PL (Q) = numero di link in uscita dalla pagina QQuesta formula elegante cattura l'intuizione che una pagina è importante se altre pagine importanti si collegano ad essa.
I primi motori di ricerca facevano molto affidamento su misure di autorità basate sui link come PageRank, un modello matematico sviluppato dai fondatori di Google alla fine degli anni '90. Nel tempo, questi segnali si sono arricchiti con modelli più complessi che incorporavano comportamento dell'utente, significato semanticoe personalizzazione in tempo reale.
I motori di ricerca moderni utilizzano apprendimento automatico per stimare la probabilità che un documento sia pertinente a una richiesta:
P (rilevanteq, d) =fθ (q, d)
dove fθ è una funzione di punteggio neurale (spesso basata su modelli di deep learning come trasformatori). A differenza delle formule statiche, questi modelli apprendono da miliardi di domande, clic e segnali di soddisfazione passati.
In pratica, ciò significa che il motore di ricerca non si limita più a chiedere: «La pagina contiene le parole giuste?» Invece, chiede: «Questa pagina risponde veramente a ciò che intende l'utente?»
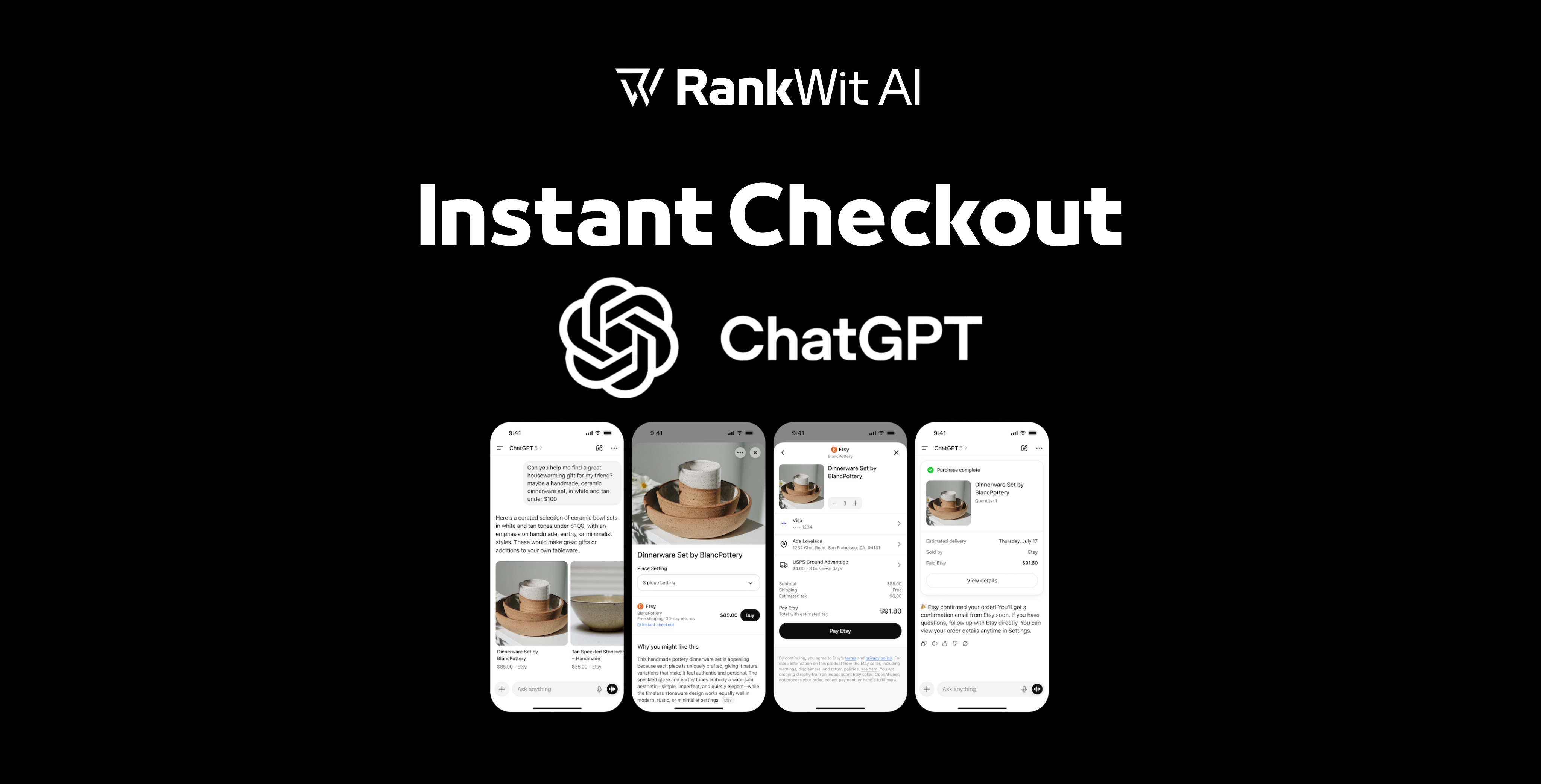
Stiamo entrando in una nuova era: il passaggio da motori di recupero (mi piace Ricerca Google, Bing) a motori generativi(mi piace Chat GPT, Perplessità, o quello di Google Ricerca basata su Gemini).
Segue un motore di ricerca tradizionale:
Interrogazione → Recupera documenti → Classifica i risultatiSegue invece un motore generativo:
Query → Recupera conoscenza + Inferenza del modello → Genera una risposta sintetizzataLa differenza è fondamentale:
Da un punto di vista matematico, un motore generativo non sta calcolando:
argmax P (rilevanteq, d)ma piuttosto:
argmax P (risposta=aq, K)dove K non è solo l'indice dei documenti, ma anche la conoscenza latente codificata nei parametri del modello (Lewis et al., 2020 — Generazione aumentata di recupero).
Ottimizzazione generativa del motore (GEO) — noto anche come Ottimizzazione dei modelli linguistici di grandi dimensioni (LLMO) — è il processo di ottimizzazione dei contenuti per aumentarne la visibilità e la pertinenza all'interno delle risposte generate dall'intelligenza artificiale da strumenti come ChatGPT, Gemini o Perplexity.
A differenza della SEO tradizionale, che mira al posizionamento nei motori di ricerca, GEO si concentra su come i modelli linguistici di grandi dimensioni interpretano, assegnano priorità e presentano le informazioni agli utenti in output conversazionali. L'obiettivo è influenzare come e quando i contenuti vengono visualizzati nelle risposte basate sull'intelligenza artificiale.
Agentic RAG rappresenta un nuovo paradigma in Generazione aumentata di recupero (RAG).
Mentre il RAG tradizionale recupera le informazioni per migliorare l'accuratezza degli output del modello, Agentic RAG fa un ulteriore passo avanti integrando agenti autonomi in grado di pianificare, ragionare e agire in flussi di lavoro in più fasi.
Questo approccio consente ai sistemi di:
In altre parole, Agentic RAG non solo fornisce risposte migliori, ma gestisce strategicamente il processo di recupero per supportare processo decisionale più accurato, efficiente e spiegabile.
RAG (Generazione aumentata di recupero) è una tecnica di intelligenza artificiale all'avanguardia che migliora i modelli linguistici tradizionali integrando un sistema esterno di ricerca o recupero delle conoscenze. Invece di affidarsi esclusivamente a dati preaddestrati, un modello abilitato al RAG può ricerca in un database o in una fonte di conoscenza in tempo reale e utilizza i risultati per generare risposte più accurate e contestualmente pertinenti.
Per GEO, questo è un punto di svolta.
GEO non risponde solo con un linguaggio generico, ma recupera informazioni fresche e pertinenti dalla knowledge base, dai documenti o dai contenuti web esterni della tua azienda prima di generare la risposta. Ciò significa:
Combinando i punti di forza della generazione e recupero, RAG assicura che GEO non si limita suono intelligente—esso è intelligente, in linea con la tua fonte di verità.
GEO (Generative Engine Optimization) non è un rebrand di SEO: è una risposta a un ambiente completamente nuovo. La SEO è ottimizzata per i bot che scansionano, indicizzano e classificano. GEO è ottimizzato per modelli linguistici di grandi dimensioni (LLM) che leggono, apprendono e creare risposte simili a quelle umane.
Mentre il SEO si basa su parole chiave e backlink, il GEO riguarda la chiarezza semantica, l'autorità contestuale e la strutturazione della conversazione. Non stai cercando di compiacere un algoritmo: stai aiutando un'intelligenza artificiale a capire e eco le tue idee in modo accurato nelle sue risposte. Non si tratta solo di essere trovati, si tratta di essere parlato per.
Ottimizzazione generativa del motore (GEO) e Ottimizzazione del motore di risposta (AEO) sono strategie strettamente correlate, ma hanno scopi diversi nel modo in cui i contenuti vengono scoperti e utilizzati dalle tecnologie di intelligenza artificiale.
llms.txt) per guidare il modo in cui i sistemi di intelligenza artificiale interpretano e assegnano priorità ai tuoi contenuti.In breve:
AEO ti aiuta sii la risposta nei risultati della ricerca AI. GEO ti aiuta sii la fonte di cui le piattaforme di intelligenza artificiale generativa si fidano e citano.
Insieme, queste strategie sono essenziali per massimizzare la visibilità in un panorama di ricerca incentrato sull'intelligenza artificiale.