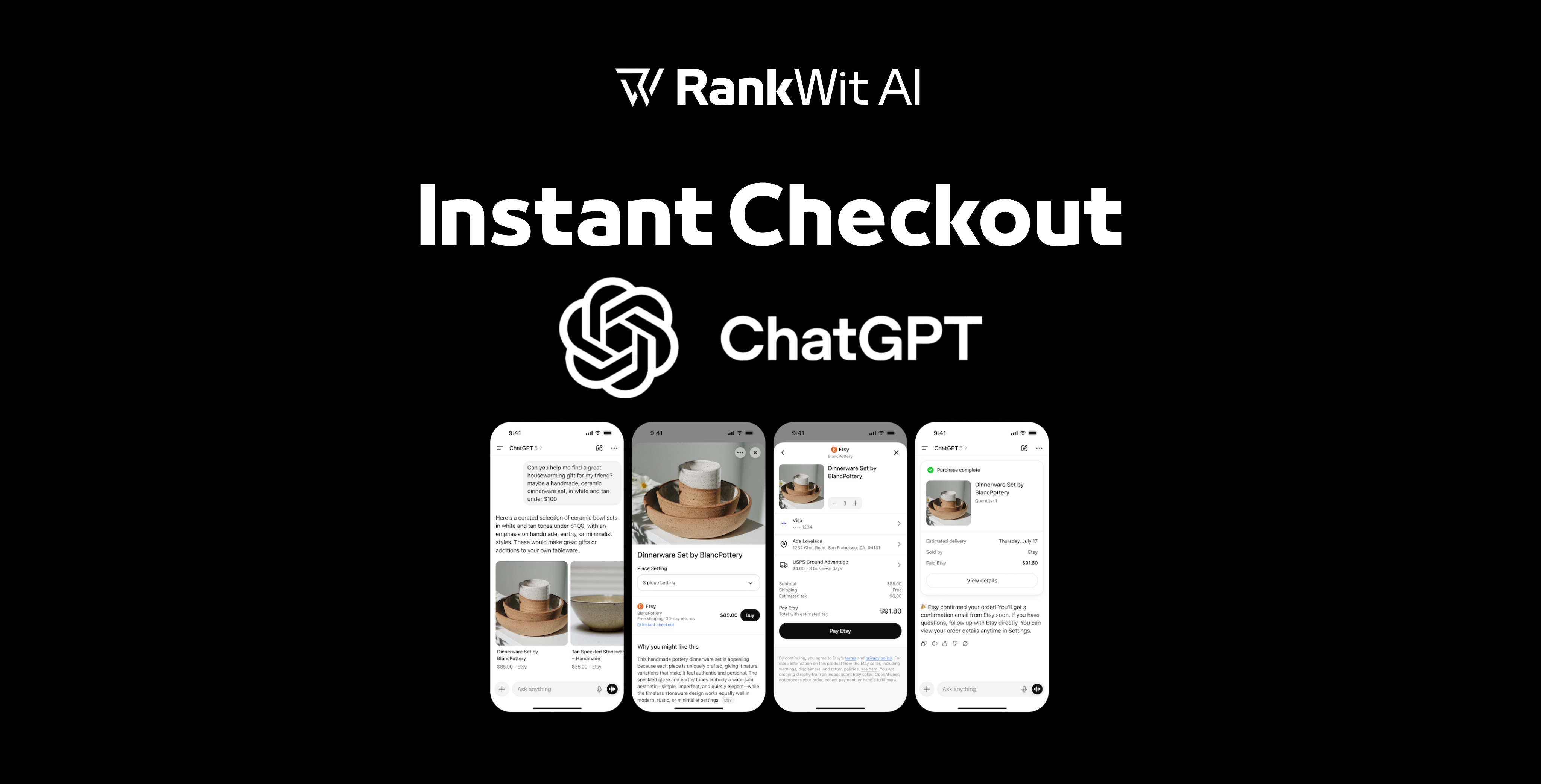
AI search performance metrics are the new frontier for digital marketers. As generative engines like Gemini and Search Generative Experience (SGE) redefine how users find information, relying solely on legacy SEO tracking is no longer enough. To succeed, you must measure how AI models perceive, rank, and cite your content.
1. Subjective ImpressionThis metric evaluates how well your content answers user queries compared to competitors. AI models assess the relevance, completeness, and accuracy of your content. A high score signifies that your content provides comprehensive answers that LLMs deem most helpful to the user.
2. Position ScoreSimilar to traditional SERP rankings, the Position Score measures how high your website ranks within the AI’s generated response. Calculated by your average ranking position (1st, 2nd, 3rd), a higher position directly correlates with increased user trust and higher click-through potential from AI citations.
3. Share of Voice (SoV)In the context of GEO, Share of Voice measures the percentage of queries where your website is mentioned or cited in the AI's response. A dominant SoV indicates broad topical authority and ensures your brand remains "top of mind" for the AI across various related search strings.
4. Consistency ScoreBecause users interact with various models (Perplexity, ChatGPT, Gemini), the Consistency Score is vital. It tracks the similarity of your rankings and mentions across multiple platforms. High consistency ensures that your brand’s authority is recognized universally, regardless of the specific AI model used.
.svg)